Understanding Knowledge Management and Distributed Systems
TLDR: Knowledge Management (KM) involves capturing, sharing, and applying knowledge within organizations. Distributed Systems use clusters and distributed file systems to manage large-scale data. NoSQL databases offer scalability and flexibility for handling unstructured data. Understanding the DIKW model, tacit vs. explicit knowledge, and the CAP theorem is essential for leveraging data effectively.
In today’s rapidly evolving technological landscape, understanding the intricacies of Knowledge Management and Distributed Systems is crucial for organizations aiming to leverage data effectively. This article delves into the foundational concepts of Knowledge Management, explores the architecture and benefits of Distributed Systems, and examines the role of NoSQL databases in handling large-scale data. By comprehending these topics, readers will gain insights into how modern systems manage, distribute, and utilize data to drive informed decision-making and maintain competitive advantage.
The DIKW Model
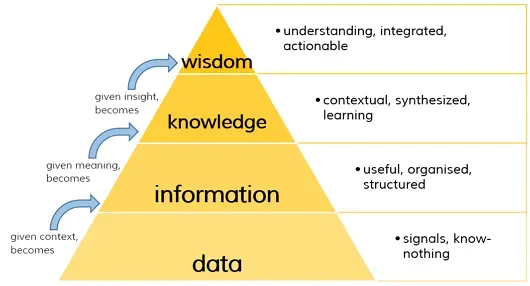
The DIKW model illustrates the relationship between data, information, knowledge, and wisdom. Data forms the base of the pyramid as unprocessed facts. When structured, data becomes information. With context, information transforms into knowledge. Wisdom represents the application of knowledge in decision-making.
Tacit vs. Explicit Knowledge
Tacit knowledge is personal and experiential, often difficult to articulate or codify. For example, a manager’s personal experience and intuition developed over years. In contrast, explicit knowledge is easily documented and shared, such as a user manual for a machine.
Knowledge Management
In Knowledge Management (KM), a “knowledge crash” refers to the loss of valuable tacit knowledge due to retirements and turnover. This loss can significantly impact organizations as critical knowledge embedded in employees is lost.
Knowledge Management Systems (KMS) enhance organizational performance by facilitating the creation, sharing, and application of knowledge. Explicit knowledge, stored in documents or databases, supports standard operating procedures. For instance, healthcare protocols stored in digital repositories. Tacit knowledge, embedded in individuals, is crucial for creativity and problem-solving. In education, experienced teachers mentoring new teachers exemplifies this. KMS have been successfully implemented in various sectors, such as healthcare, education, and business, leading to better treatment outcomes, enhanced collaborative learning, and retention of expertise.
Clusters and Distributed File Systems
Clusters are tightly coupled collections of servers or nodes working together to execute tasks by distributing parts of the task across different computers. This enables large-scale data processing by utilizing the combined resources of multiple machines. Clusters improve scalability and fault tolerance, offering increased processing power by parallelizing tasks across nodes.
Traditional file systems store data locally on a single machine, while distributed file systems spread large files across multiple nodes in a cluster. Examples include Google File System (GFS) and Hadoop Distributed File System (HDFS), which ensure fault tolerance and scalability.
NoSQL Databases
NoSQL databases are non-relational databases designed to store and manage large volumes of unstructured and semi-structured data. They provide horizontal scalability, fault tolerance, and flexibility in data models. Examples of query languages used by NoSQL databases include XQuery and SPARQL.
Sharding and Replication
Sharding is the process of horizontally partitioning a large dataset into smaller, more manageable pieces called shards, distributed across multiple nodes. This improves database performance by balancing the load across different machines. However, performance penalties can occur when queries require data from multiple shards.
Replication involves storing multiple copies of data on different nodes, enhancing data availability, fault tolerance, and load balancing. Master-slave replication and peer-to-peer replication are two approaches, each with its advantages and challenges.
CAP Theorem and ACID vs. BASE
The CAP theorem states that a distributed database can only provide two of the following three properties: Consistency, Availability, and Partition tolerance. A distributed system cannot achieve all three properties simultaneously. For example, prioritizing Consistency and Partition tolerance may compromise Availability.
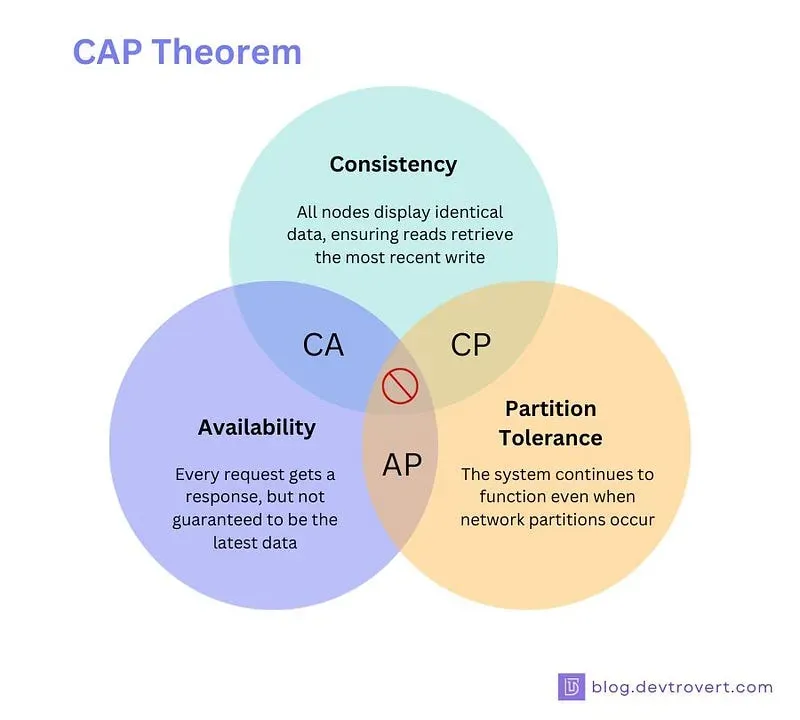
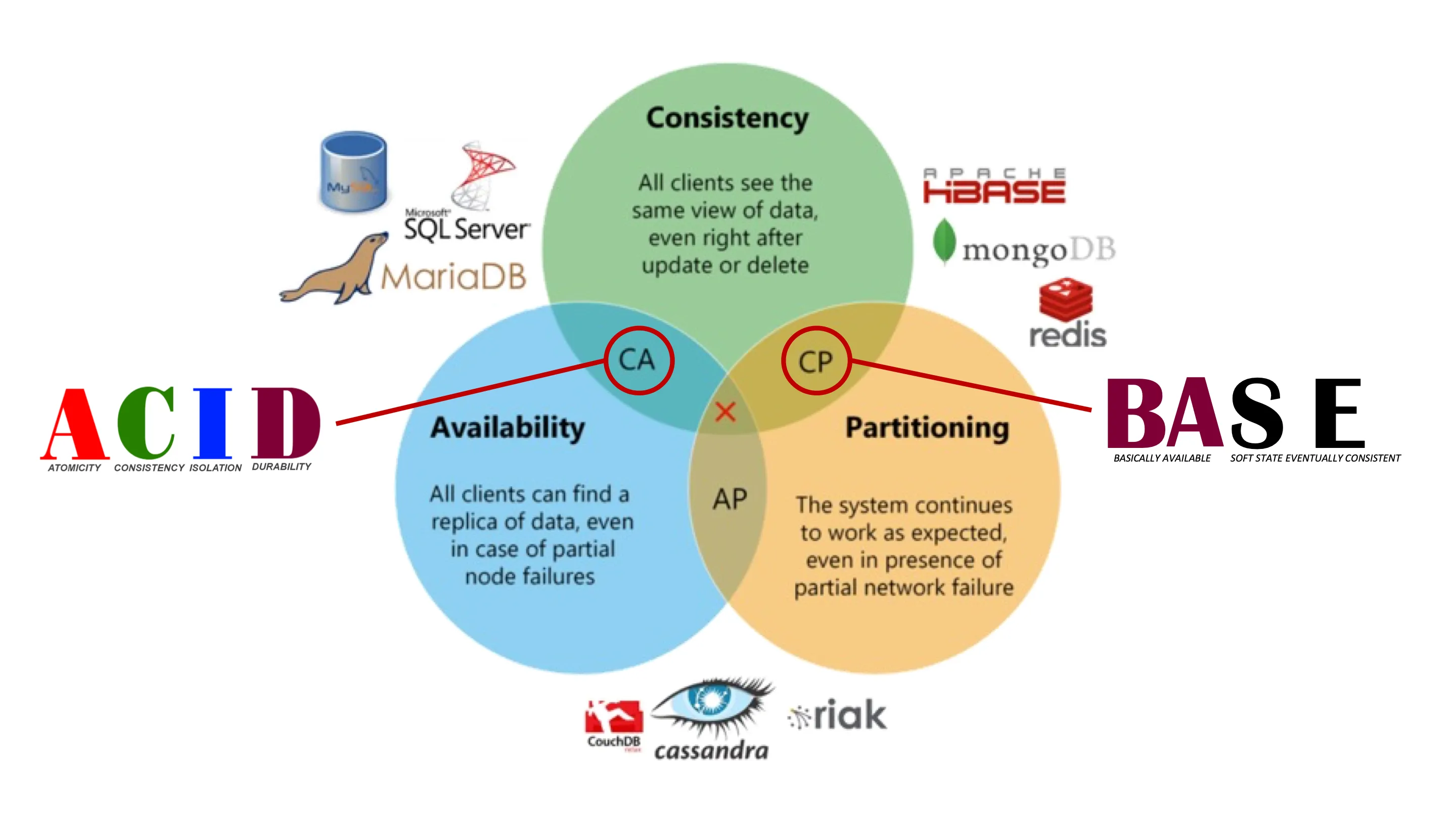
The ACID properties (Atomicity, Consistency, Isolation, Durability) ensure transactional consistency and reliability but can reduce performance in distributed systems. In contrast, BASE properties (Basically available, Soft state, Eventual consistency) offer higher availability and can tolerate some inconsistency, suitable for systems like social media platforms.
.Ci3PlevB_67QUH.webp)
.BREVM4-l_21OWLJ.webp)
Combining Sharding with Replication
Combining sharding with replication improves scalability and fault tolerance. Sharding with master-slave replication provides strong consistency for writes but can suffer from master node failures. Sharding with peer-to-peer replication improves fault tolerance and availability but may lead to temporary inconsistencies during write operations.
Example Case Study
ETI’s IT environment currently uses both Linux and Windows operating systems with relational databases implementing ACID principles. Considering the company is expanding its infrastructure to include big data storage.
ETI’s IT environment could benefit from implementing a BASE-compliant NoSQL system for their big data storage needs. Unlike ACID systems, which prioritize consistency and strict transactional integrity, BASE systems offer higher availability and can tolerate temporary inconsistencies. This approach is more suitable for ETI, enabling efficient scaling while maintaining system availability.
Conclusion
Knowledge Management and Distributed Systems play a vital role in modern organizations, enabling efficient data management, sharing, and utilization. By understanding the DIKW model, tacit vs. explicit knowledge, and the architecture of distributed systems, organizations can leverage data effectively to drive informed decision-making and maintain a competitive edge in today’s data-driven world. NoSQL databases, sharding, replication, and the CAP theorem provide essential tools and concepts for managing large-scale data and ensuring system reliability and scalability. By implementing these strategies, organizations can optimize their data infrastructure and adapt to the evolving demands of the digital landscape.